引言
本文为阅读TMCache源码后所产,TMCache由著名网站tumblr开发虽然目前已停止维护,源码中还是有很多值得借鉴的点。客户端缓存从硬件介质上来看,无非就是内存和磁盘两种。在TMCache中分别对应TMMemoryCache(内存级别缓存)、TMDiskCache(磁盘级别缓存)。通常来讲磁盘缓存由于涉及磁盘IO、文件编解码较内存缓存而言会更复杂一些。本文中笔者将循着TMCache的实现分析TMMemoryCache、TMDiskCache源码中一些平时开发中值得借鉴的点(红榜)及一些需要避免的点(黑榜)。
PS:为方便阅读、聚焦本文讨论的key点,本文中对所引入的TMCache源码进行不同程度的精简。
TMMemoryCache
TMMemoryCache提供了线程安全的同步/异步读写内存的API。对于内存缓存而言并行读、串行写是刚需(即读写锁),TMMemoryCache对于读写线程安全访问控制及异步转同步的实现值得借鉴。
TMMemoryCache红榜之读写锁实现
TMMemoryCache通过GCD并发队列及 dispatch_barrier_async()实现并发读、串行写的线程安全访问。
dispatch_barrier_async
一个比较关键的概念是:dispatch_barrier_async(),dispatch_barrier_async()是GCD提供的类似“内存屏障”的“队列屏障”。dispatch_barrier_async()在GCD并发队列的任务调度中起到一个栅栏的作用,dispatch_barrier_async()提交到队列里的任务会等待之前的任务执行完毕,再开始执行。且dispatch_barrier_async()提交到队列里的任务执行完毕后才会执行之后之后提交到队列里的任务。一图以蔽之:
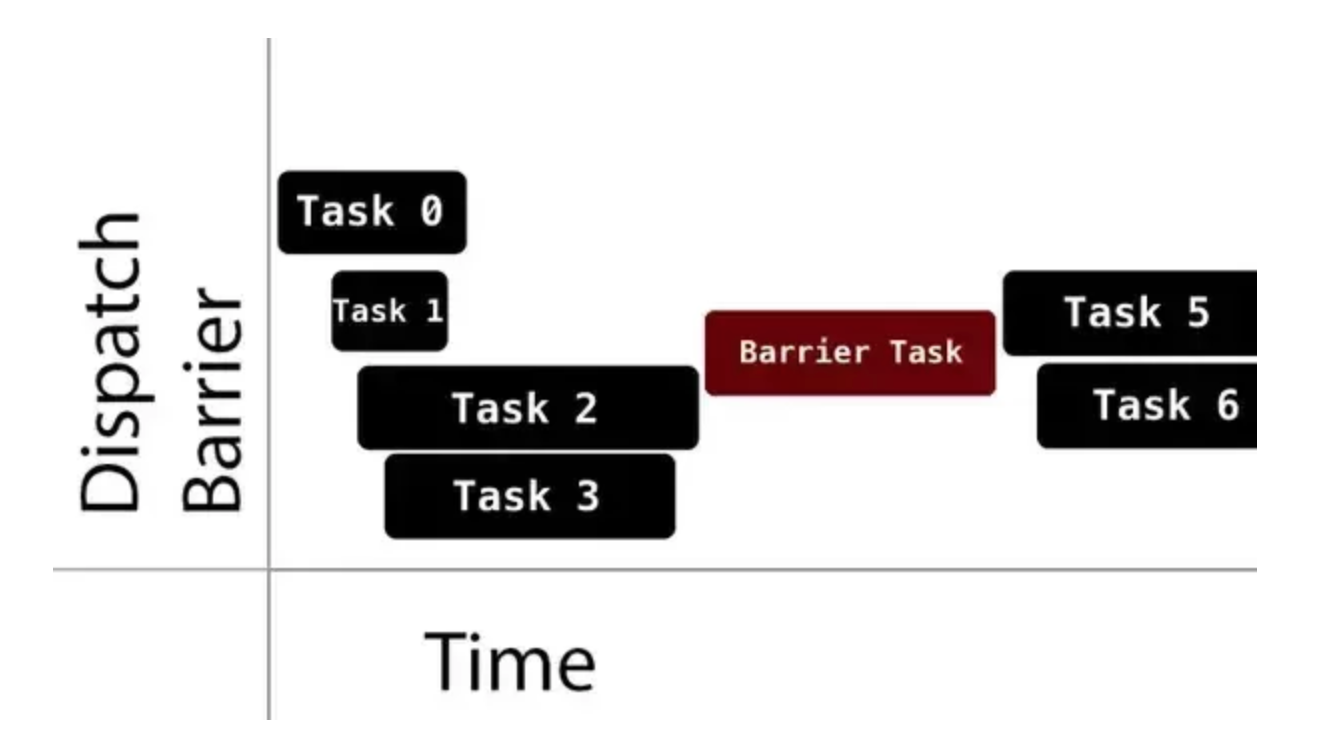
TMMemoryCache中读写操作都是在一个 concurrent queue(并发队列)中, 通过 dispatch_barrier_async() 保障在同一时间只有一个写任务在执行, 其它读写操作都处于等待状态, 这是 TMMemoryCache 保证线程安全的核心。
部分源码
一起来看一下简化后的源码:
读操作
1 | - (void)objectForKey:(NSString *)key block:(TMMemoryCacheObjectBlock)block |
写操作
1 | - (void)setObject:(id)object forKey:(NSString *)key withCost:(NSUInteger)cost block:(TMMemoryCacheObjectBlock)block |
TMMemoryCache红榜之异步转同步实现
TMMemoryCache的同步方法是通过在调用异步方法的过程中插入dispatch_semaphore_t信号量实现的。
1 | - (void)setObject:(id)object forKey:(NSString *)key withCost:(NSUInteger)cost |
###TMMemoryCache黑榜之线程爆炸
在实际使用过程中,通过GCD Barrier来保证读写同步在一定程度上是可行的,但在并发量很大的情况,会造成线程爆炸,严重情况下会因为线程资源消耗而导致死锁。一起来看一个例子,我们通过以下代码来模拟通过TMMemoryCache高并发下读写缓存的case:
1 | #define TIMES 1000000 |
通过断点看一下执行过程中的线程状况:
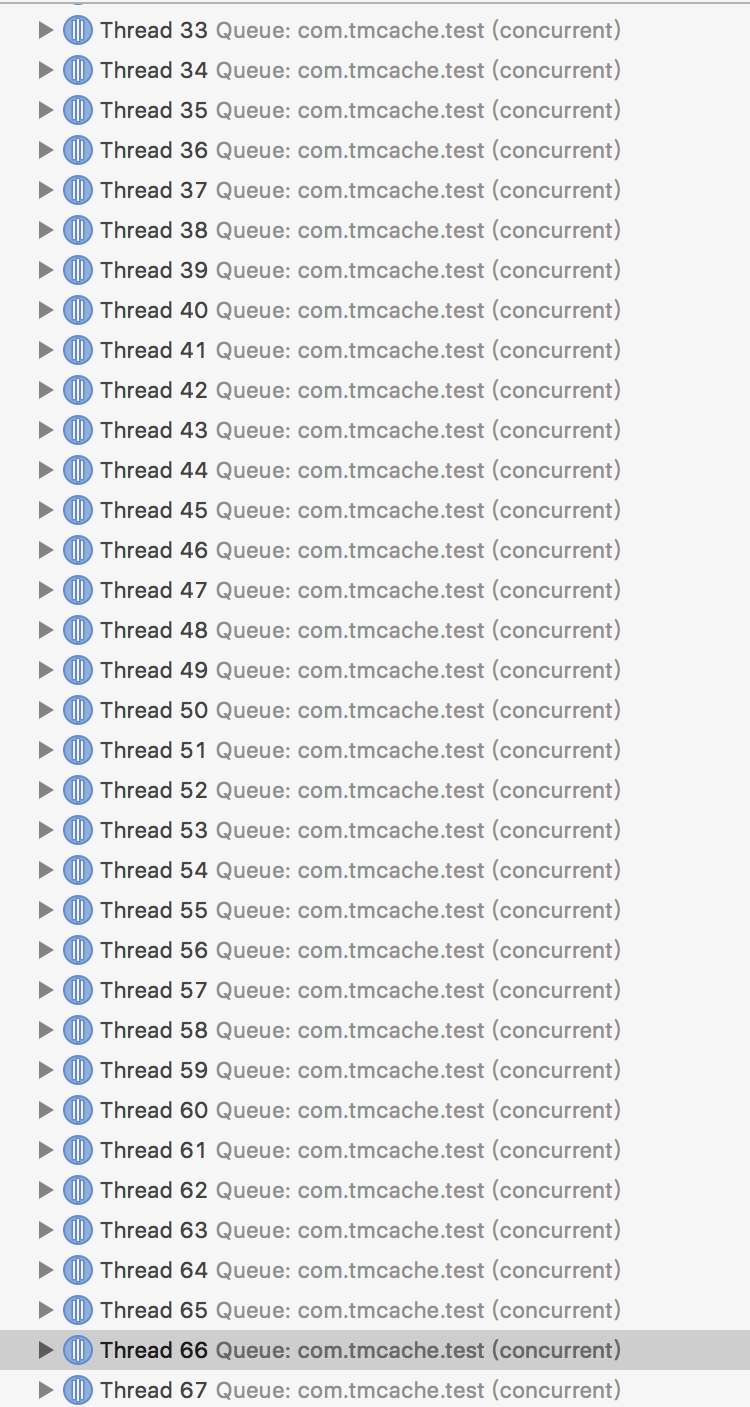
其实在当前case下已经产生死锁了。
这是由于GCD的特性导致的。GCD创建了一个大致与内核数量相匹配的线程池,如果我们向GCD提交了一个任务,并且该任务阻塞了该线程。为了弥补线程被阻塞的损失,GCD会创建一个新的线程并将其添加到线程池中,这就是线程爆炸的根本原因。同时,由于线程并不是免费资源,每一个线程都需要固定的内存(用于存储线程局部信息函数调用栈等)和内核(用于线程调度)资源,大量分配线程会导致内核资源耗尽导致死锁。
这也是平时开发中需要注意的点:对于高并发下的读写操作应避免使用GCD Barrier,可以通过封装NSLock实现一个自定义的读写锁。
TMDiskCache
TMDiskCache的实现形式是基于文件读写的。TMDiskCache同样提供了线程安全的同步/异步读写磁盘的API。其异步转同步思路与TMMemoryCache一致这里不再赘述。关于TMDiskCache我们关注的重点不再是线程安全(TMDiskCache所有的读写操作都在一个 serial queue 串行队列中, 不存在竞态情况,),而作者根据磁盘缓存的特性对于API的选择很有借鉴意义。
TMDiskCache红榜之serial queue
不同于TMMemoryCache,TMCache的作者将TMDiskCache的读写操作放在了一个 serial queue。这是由于磁盘存取的速度瓶颈在磁盘IO上,和是否多线程存取没有太大关系。磁盘IO是一个很复杂的课题,这里只列出几点关于TMCache作者选用serial queue的猜想,不做展开讨论。
磁盘IO调度层本身就是串行
调用上层API产生的磁盘IO请求会被放到IO调度层,在IO调度层会缓存请求并试图合并请求,最终内核根据设置好的调度算法,回调驱动层提供的请求处理函数,以处理具体的I/O请求。而磁盘I/O调度层本身的调度策略就是串行的,这主要是由于目前计算机体系结构下磁盘是不支持多磁头同时读写的。
磁盘Cache层提供了足够的优化
磁盘Cache层在内存中缓存了磁盘上的部分数据。当数据请求到达时,如果Cache存在数据且是最新的,则将数据传递给用户程序,免除了对底层磁盘的操作,提高了性能。
磁盘Cache有两大功能:预读和回写。
预读
预读其实就是利用了局部性原理,具体过程是:对于每个文件的第一个读请求,系统读入所请求的页面并读入紧随其后的少数几个页面(通常是三个页面),这时的预读称为同步预读。对于第二次读请求,如果所读页面不在Cache中,即不在前次预读的页中,则表明文件访问不是顺序访问,系统继续采用同步预读;如果所读页面在Cache中,则表明前次预读命中,操作系统把预读页的大小扩大一倍,此时预读过程是异步的,应用程序可以不等预读完成即可返回,只要后台慢慢读页面即可,这时的预读称为异步预读。任何接下来的读请求都会处于两种情况之一:第一种情况是所请求的页面处于预读的页面中,这时继续进行异步预读;第二种情况是所请求的页面处于预读页面之外,这时系统就要进行同步预读。
回写
回写是通过暂时将数据存在Cache里,然后统一异步写到磁盘中。通过这种异步的数据I/O模式解决了程序中的计算速度和数据存储速度不匹配的鸿沟,减少了访问底层存储介质的次数,使存储系统的性能大大提高。
多线程下的磁盘I/0
有了这些基础我们再来分别看一下多个线程调用读和写分别会发生什么。
多个线程同时读
在未命中磁盘Cache的情况下,会提交多个I/O任务到磁盘I/O调度层。可能依靠IO调度层本身的调度算法及对于同一文件I/O请求的合并带来效率上的些许提升。但是比起CPU消耗及多个线程上下文切换其意义并不是很大。而且对于同一文件I/O请求在串行发起多次的情况下,除第一次I/O请求会读磁盘外其余都会命中磁盘Cache,所以I/O调度层对于同一文件I/O请求的合并不会带来实际的意义。
多个线程同时写
根据磁盘Cache的回写功能,不难看出多线程同时写只是更快的填满了写缓冲区,并不会带来实际意义上的效率提升。
TMDiskCache红榜之文件删除
关于文件删除TMDiskCache的实现方案是将待删除文件移至tmp文件夹,然后将具体的删除任务丢到优先级最低的DISPATCH_QUEUE_PRIORITY_BACKGROUND去做。这样只有在程序真正空闲时才会处理具体删除操作。如果程序最终都没有处理删除操作在程序,在程序结束后系统会自动删除tmp文件夹内的文件。一起来看一下相关源码吧:
文件删除源码
共享的文件删除队列(DISPATCH_QUEUE_PRIORITY_BACKGROUND优先级)
1 | + (dispatch_queue_t)sharedTrashQueue |
共享的存放删除文件的tmp文件夹
1 | + (NSURL *)sharedTrashURL |
待删除文件移动至tmp文件夹,这里另外一个点是通过调用[[NSProcessInfo processInfo] globallyUniqueString]生成了一个临时文件名,该方法会确保每次“调用”会不一样,所以不会产生相同的文件名。
1 | +(BOOL)moveItemAtURLToTrash:(NSURL *)itemURL |
清空操作,遍历并删除tmp文件夹下所有文件,该任务被丢到DISPATCH_QUEUE_PRIORITY_BACKGROUND优先级队列中执行。
1 | + (void)emptyTrash |
TMDiskCache黑榜之不当API使用
一起来看TMDiskCache中以下代码:
1 | - (void)setAgeLimit:(NSTimeInterval)ageLimit |
这里注意两点:
- _queue 为串行队列
- 使用了dispatch_barrier_async()栅栏函数
所以上面的代码是在串行队列中使用了栅栏函数??难道串行队列不是保障了任务按入队顺序依次执行且上一个执行完毕才会执行下一个??关于dispatch_barrier_async()一起来看一下苹果爸爸怎么说:
The queue you specify should be a concurrent queue that you create yourself using the dispatch_queue_create function. If the queue you pass to this function is a serial queue or one of the global concurrent queues, this function behaves like the dispatch_async function.
如果我们传入非自定义队列或串行队列那使用dispatch_barrier_async()函数就等于是在用 dispatch_async()。滥用API有木有,虽然不会产生性能、质量上的影响但的确是一个槽点。